






Newsletter Subscribe
Enter your email address below and subscribe to our newsletter
Enter your email address below and subscribe to our newsletter
All voices matter
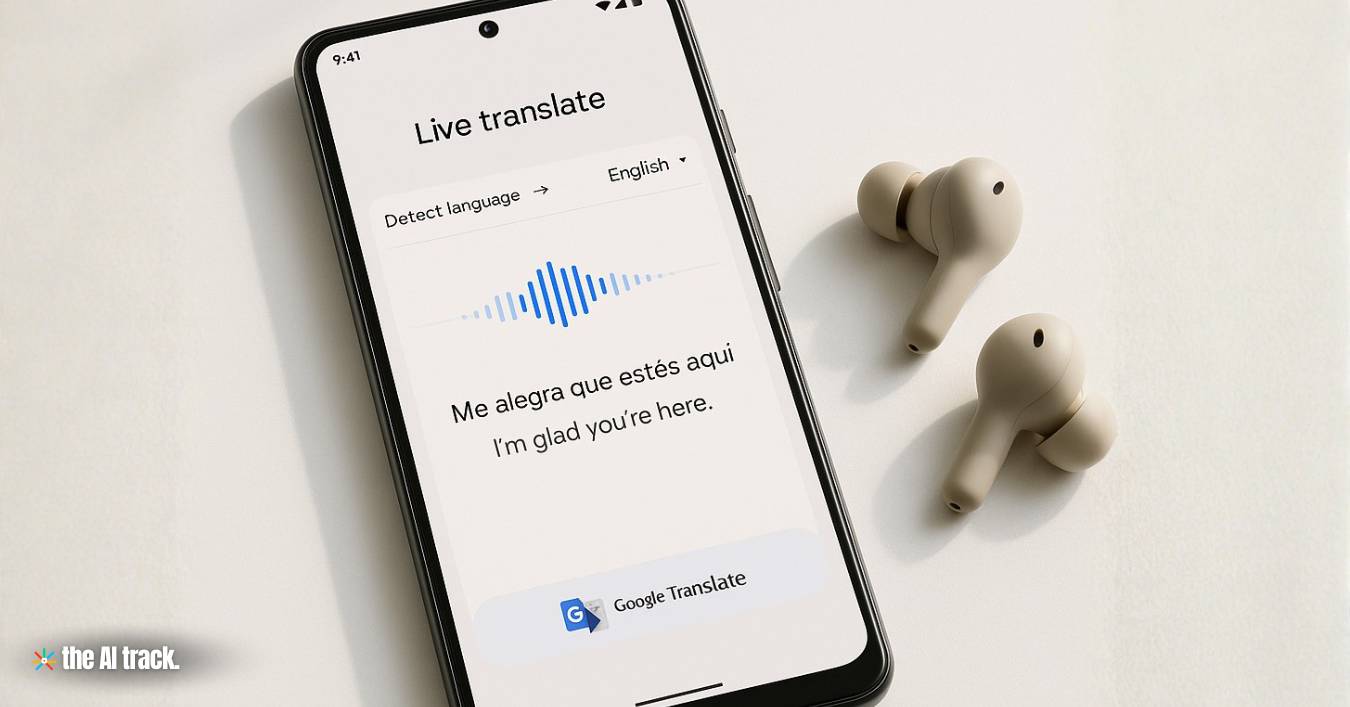
Google on Tuesday released Gemini 3.5 Live Translate, an AI-powered audio model that translates speech in near real time across more than 70 languages, marking one of the company’s most ambitious deployments of on-device translation technology. The same day, Google DeepMind introduced DiffusionGemma, an experimental open model that generates text up to four times faster than standard autoregressive models by applying diffusion techniques to the Gemma 4 architecture.
Gemini 3.5 Live Translate departs from conventional turn-by-turn translation systems that wait for a speaker to finish before producing output. Instead, the model processes and translates speech continuously, staying just a few seconds behind the speaker while preserving intonation, pacing, and pitch.blog
The model is rolling out across three surfaces: globally on the Google Translate app for Android and iOS, in public preview for developers via the Gemini Live API and Google AI Studio, and in private preview for select Google Workspace business customers on Google Meet starting this month. The Meet integration expands speech translation from five previously supported languages to more than 70, enabling over 2,000 language combinations in a single meeting.9to5google
A new “listening mode” on Android allows users to hear translations through their phone’s earpiece without headphones — simply by holding the device to their ear like a regular call. All generated audio is watermarked with SynthID to help identify AI-generated content.indiatoday
Separately, Google DeepMind released DiffusionGemma, a 26-billion-parameter mixture-of-experts model that generates text the way image diffusion models create pictures — starting from noise and refining entire blocks of up to 256 tokens in parallel rather than predicting one word at a time.nvidia
Built on the Gemma 4 architecture and activating only 3.8 billion parameters during inference, DiffusionGemma achieves over 1,000 tokens per second on a single Nvidia H100 GPU and roughly 700 tokens per second on a consumer GeForce RTX 5090. The model weights are available on Hugging Face under the Apache 2.0 open-source license.blog
Google CEO Sundar Pichai highlighted DiffusionGemma on social media, calling it “a racehorse achieving up to 4x faster inference” that brings the company’s text diffusion research to the Gemma 4 family.x
Google cautioned that DiffusionGemma is experimental and trails standard Gemma 4 on output quality benchmarks, recommending it primarily for speed-critical local workflows such as inline editing, rapid iteration, and agentic loops rather than production deployments requiring maximum quality. Nvidia has optimized the model across its hardware lineup, from consumer GPUs to DGX Spark systems, with day-one support in vLLM, Hugging Face Transformers, and Unsloth.thenewstack








