
Newsletter Subscribe
Enter your email address below and subscribe to our newsletter
Enter your email address below and subscribe to our newsletter
All voices matter
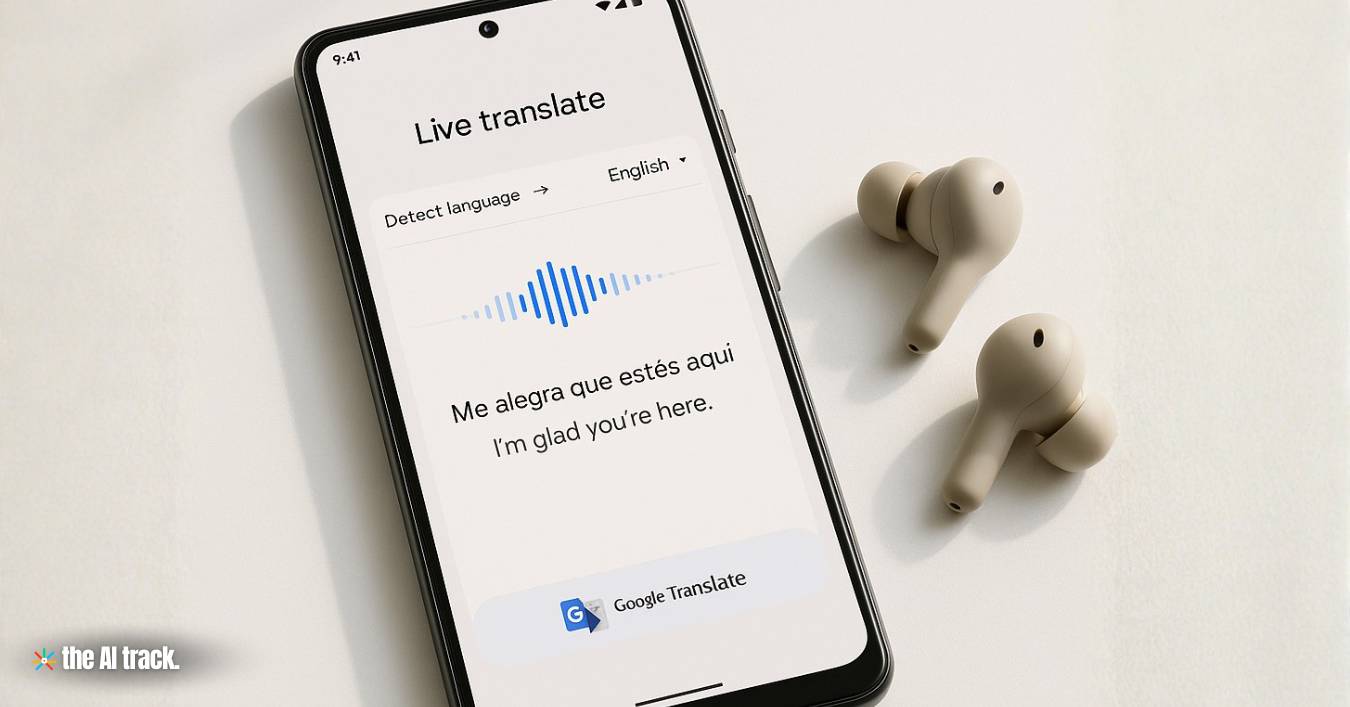
Google-მა სამშაბათს გამოუშვა Gemini 3.5 Live Translate, ხელოვნურ ინტელექტზე დაფუძნებული აუდიომოდელი, რომელიც თარგმნის მეტყველებას თითქმის რეალურ დროში 70-ზე მეტ ენაზე, რაც კომპანიის ერთ-ერთი ყველაზე ამბიციური ნაბიჯია მოწყობილობაში ჩაშენებული თარგმნის ტექნოლოგიის სფეროში. იმავე დღეს, Google DeepMind-მა წარადგინა DiffusionGemma, ექსპერიმენტული ღია მოდელი, რომელიც ტექსტს სტანდარტულ ავტორეგრესიულ მოდელებზე ოთხჯერ უფრო სწრაფად გენერირებს Gemma 4 არქიტექტურაზე დიფუზიური ტექნიკის გამოყენებით.
Gemini 3.5 Live Translate განსხვავდება ჩვეულებრივი თარგმნის სისტემებისგან, რომლებიც ელოდებიან მოსაუბრის დასრულებას შედეგის გამოსატანად. ამის ნაცვლად, მოდელი ამუშავებს და თარგმნის მეტყველებას უწყვეტად, მოსაუბრეს მხოლოდ რამდენიმე წამით ჩამორჩება და ინარჩუნებს ინტონაციას, ტემპს და სიმაღლეს.blog
მოდელი ვრცელდება სამ პლატფორმაზე: გლობალურად Google Translate-ის აპლიკაციაში Android-ისა და iOS-ისთვის, საჯარო წინასწარი ნახვის რეჟიმში დეველოპერებისთვის Gemini Live API-სა და Google AI Studio-ს მეშვეობით, და დახურულ წინასწარი ნახვის რეჟიმში Google Workspace-ის ბიზნეს მომხმარებლებისთვის Google Meet-ში ამ თვიდან. Meet-ის ინტეგრაცია აფართოებს მეტყველების თარგმნას ხუთი ადრე მხარდაჭერილი ენიდან 70-ზე მეტამდე, რაც საშუალებას იძლევა 2000-ზე მეტი ენობრივი კომბინაცია ერთ შეხვედრაში.9to5google
Android-ზე ახალი „მოსმენის რეჟიმი“ მომხმარებლებს საშუალებას აძლევს მოისმინონ თარგმანი ტელეფონის ყურსასმენის მეშვეობით ყურსასმენების გარეშე — უბრალოდ მოწყობილობის ყურთან მიტანით, როგორც ჩვეულებრივი ზარის დროს. ყველა გენერირებული აუდიო აღინიშნება SynthID წყლის ნიშნით, რათა დაეხმაროს ხელოვნური ინტელექტის მიერ შექმნილი კონტენტის იდენტიფიცირებას.indiatoday
ცალკე, Google DeepMind-მა გამოუშვა DiffusionGemma, 26-მილიარდ-პარამეტრიანი ექსპერტების ნარევის მოდელი, რომელიც ტექსტს გენერირებს ისევე, როგორც გამოსახულების დიფუზიური მოდელები ქმნიან სურათებს — იწყებს ხმაურიდან და აუმჯობესებს 256-მდე ტოკენის მთლიან ბლოკებს პარალელურად, ნაცვლად თითო სიტყვის თანმიმდევრული პროგნოზირებისა.nvidia
აგებული Gemma 4 არქიტექტურაზე და ინფერენციის დროს მხოლოდ 3.8 მილიარდი პარამეტრის აქტივაციით, DiffusionGemma აღწევს 1000-ზე მეტ ტოკენს წამში ერთ Nvidia H100 GPU-ზე და დაახლოებით 700 ტოკენს წამში სამომხმარებლო GeForce RTX 5090-ზე. მოდელის წონები ხელმისაწვდომია Hugging Face-ზე Apache 2.0 ღია კოდის ლიცენზიით.blog
Google-ის აღმასრულებელმა დირექტორმა Sundar Pichai-მ სოციალურ ქსელში ხაზი გაუსვა DiffusionGemma-ს და უწოდა მას „სარბოლო ცხენი, რომელიც აღწევს 4-ჯერ უფრო სწრაფ ინფერენციას“, რაც კომპანიის ტექსტური დიფუზიის კვლევას Gemma 4-ის ოჯახში აერთიანებს.x
Google-მა გააფრთხილა, რომ DiffusionGemma ექსპერიმენტულია და ჩამორჩება სტანდარტულ Gemma 4-ს გამომავალი ხარისხის მაჩვენებლებით, ამიტომ რეკომენდაციას უწევს მას ძირითადად სიჩქარეზე ორიენტირებული ლოკალური სამუშაო პროცესებისთვის, როგორიცაა ინლაინ რედაქტირება, სწრაფი იტერაცია და აგენტური ციკლები, და არა მაქსიმალურ ხარისხს მოითხოვს წარმოების დანერგვისთვის. Nvidia-მ ოპტიმიზაცია გაუკეთა მოდელს თავის აპარატურულ ხაზზე, სამომხმარებლო GPU-ებიდან DGX Spark სისტემებამდე, vLLM, Hugging Face Transformers და Unsloth-ში პირველივე დღიდან მხარდაჭერით.thenewstack








